

Support teams hit this wall around 40-50 agents. You've got deterministic rules routing billing tickets to finance specialists. Skill-based queues sending technical issues to engineers. Priority flags bumping enterprise customers. Then someone adds a region-based rule, another person layers in language preferences, and suddenly tickets are bouncing between queues like pinballs.
The real mess happens in the gaps between rules. A billing question from a Spanish-speaking enterprise customer in APAC who needs help with API integration — where does that go? Deterministic rules say billing team. Skill routing says API specialist. Priority rules say enterprise queue. Language rules say Spanish support.
Most teams end up with tickets stuck in limbo or routed to whoever's available first. Response times balloon from 2 hours to 8. Customers get passed between 3-4 agents. Your best technical people waste time on password resets while complex integration issues pile up in the general queue.
The cascade failure pattern in mixed routing systems
You start clean — product questions go to product, billing to finance, bugs to engineering. Works great for two months. Then edge cases pile up.
A customer reports what looks like a bug but is actually a billing display issue. Goes to engineering first because the "bug" keyword triggered. They investigate for 45 minutes, realize it's billing, transfer to finance. Finance sees technical jargon in the ticket history, assumes engineering made an error, sends it back. Meanwhile the customer has sent three follow-ups creating duplicate tickets that each follow different routing paths.
Things accelerate when teams start building workarounds. Engineering adds a rule to auto-reject anything with "invoice" keywords. Finance blocks tickets with "API" mentions. Support managers create override rules for VIP accounts. Now you've got 47 routing rules, 23 skill definitions, and 15 exception cases that nobody fully understands.
One 200-person support operation I worked with had tickets averaging 2.8 touches before reaching the right agent. Nearly two full transfers per ticket. Each transfer added 3-4 hours to resolution time. On 500 daily tickets, that's roughly 1,000 unnecessary agent interactions every single day.
Building a three-tier routing cascade that actually works
Forget trying to handle every scenario with one perfect rule. Layer your routing in three distinct phases with clear handoff triggers.
Never let a customer request slip through the cracks.
Helpyly helps you track, resolve, and optimize every support interaction effortlessly.
- Centralized ticket management
- Automated customer notifications
- Performance analytics dashboard
No credit card required
Tier 1: Hard deterministic rules (first 30 seconds)
These rules run immediately and handle obvious cases:
-
Refund requests → Finance team
-
Password resets → General support
-
Contract questions → Sales
-
Critical outages → Engineering on-call
Keep this tier simple. No more than 8-10 rules. Each rule checks one clear condition. If multiple conditions match, the most specific wins — a ticket matching "refund + enterprise" goes to enterprise before finance.
Tier 2: Skill-based distribution (30 seconds to 2 minutes)
Unmatched tickets enter skill evaluation. Instead of complex skill matrices, use primary and secondary skill matching:
Primary skills (must match):
-
Language requirements
-
Product knowledge (specific integrations/features)
-
Compliance certifications
Secondary skills (nice to have):
-
Industry experience
-
Previous interaction history
-
Technical depth level
Set a 90-second timeout. If no agent matches all primary skills within 90 seconds, drop the least critical requirement and re-evaluate. This stops tickets from sitting in specialized queues indefinitely.
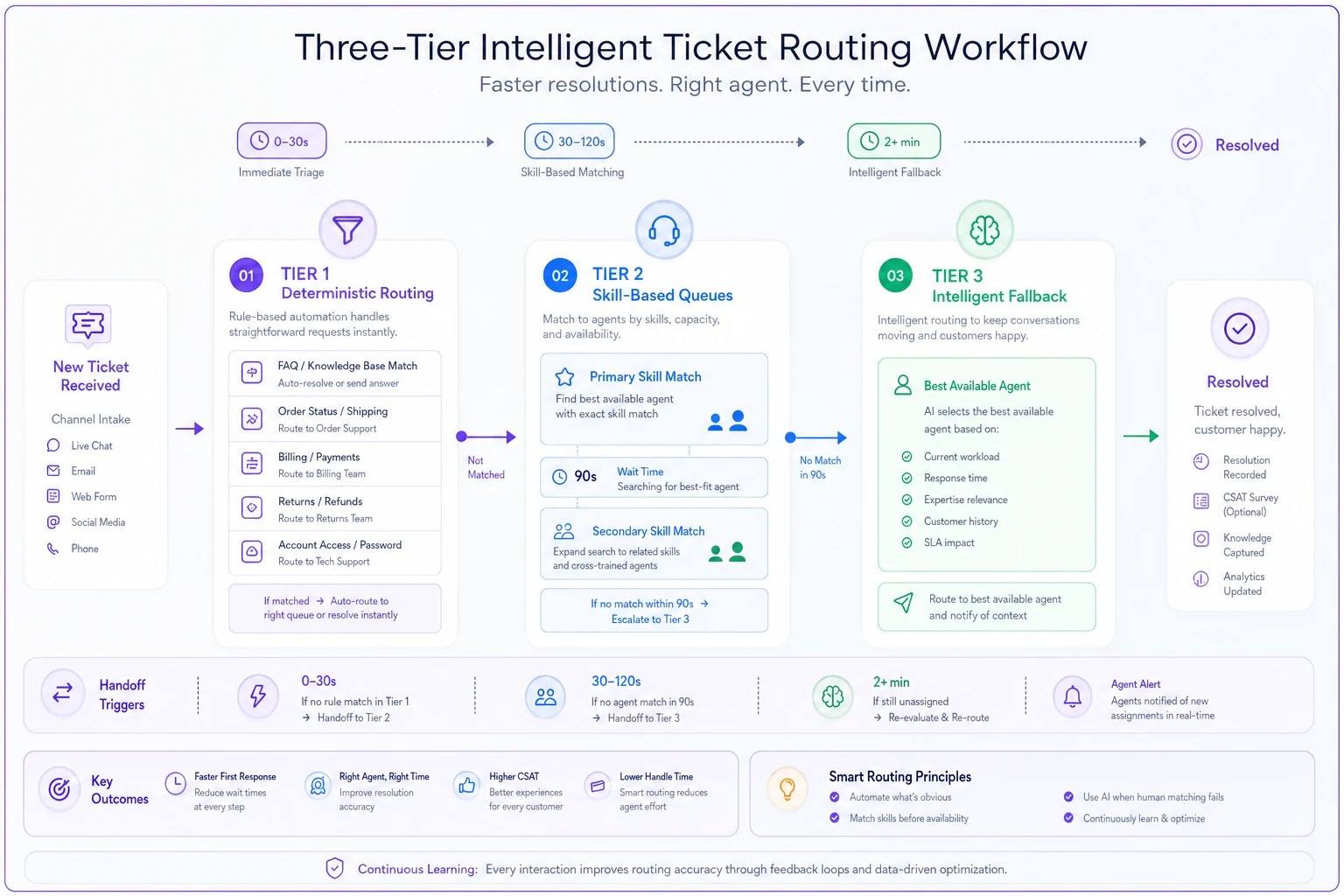
This diagram shows the handoffs between tiers and where timeouts and fallbacks trigger in the cascade.
Tier 3: Intelligent fallback (2+ minutes)
After two minutes, engage fallback routing:
-
Check general queue capacity
-
Identify agents with partial skill matches
-
Factor in current resolution times
-
Route to best available option
Track every fallback activation. If billing tickets hit fallback more than 15% of the time, you need more billing agents or better Tier 1 rules. That number is a useful canary — it tells you where your system is straining before customers start complaining.
Real routing rules that cover 80% of edge cases
Stop trying to predict every scenario. Build rules that handle patterns, not specifics.
Pattern-based rules that scale:
Instead of: "Route Shopify integration errors to Sam" Use: "Route e-commerce platform errors to agents with API certification"
Instead of: "Send Spanish VIP tickets to Maria" Use: "Route non-English priority tickets to multilingual senior agents"
Instead of: "Billing questions about annual plans go to Finance Team B" Use: "Route subscription modifications over $1,000 to senior finance"
Effective rule combinations:
Customer segment + Issue type:
-
Enterprise + Technical → Senior engineers
-
SMB + Billing → General finance
-
Free tier + Bugs → Community support
Urgency + Complexity:
-
Critical + Simple → Any available senior agent
-
Low priority + Complex → Specialized queue with longer SLA
-
High priority + Unknown → Senior generalist for triage
Channel + History:
-
Email + Previous escalation → Same agent if available
-
Chat + Multiple contacts → Priority queue
-
Phone + First contact → Skills-based routing
Anti-patterns to avoid:
-
Individual agent names (they leave, get sick, take vacation)
-
Specific product versions (these change monthly)
-
Customer company names (doesn't scale beyond 50 accounts)
-
Time-based rules without fallbacks (holidays break everything)
If you're sitting in the middle of that table — some signals pointing each direction — start with Tier 1 deterministic rules only and add skill matching once you can see where tickets are actually breaking down.
Misroute signals hiding in your ticket data
Your tickets are showing routing problems constantly — most teams just aren't looking. Every misroute leaves a trail if you know where to check.
Transfer patterns that indicate systematic problems:
-
Multiple transfers in the same category
When billing tickets get transferred between billing agents more than once, your skill definitions are wrong. Agents are drawing internal lines — "I don't do refunds, I do subscriptions" — while customers see it all as one billing team.
-
Boomerang tickets
Ticket goes from support to engineering, back to support, back to engineering. This means triage criteria are unclear. Teams are playing hot potato instead of solving problems.
-
The Friday afternoon shuffle
Tickets transferred repeatedly between 3-5pm on Fridays. Agents pushing complex issues to avoid weekend escalations. These tickets often sit untouched until Monday afternoon.
Response patterns revealing hidden misroutes:
-
The "wrong department" opener
When 20% of first responses start with "I'm forwarding this to the right team," your Tier 1 rules are failing.
-
Copy-paste investigation
Agents spending 5-10 minutes researching before responding is a sign they shouldn't have received the ticket. They're trying to figure out if it's actually their problem.
-
Silent transfers
Tickets moved without customer communication. Agents know it's misrouted but don't want to admit the mistake.
Resolution metrics exposing routing gaps:
-
Skill mismatch resolution times
When generalists resolve technical tickets faster than specialists, your skill definitions are outdated. The "specialists" might be experts in deprecated features.
-
Channel resolution variance
Email tickets taking 3x longer than chat for identical issues usually means your channel-based routing is creating artificial bottlenecks.
These signals are detectable in ticket metadata and agent activity logs if you know which queries to run.
The monitoring dashboard that catches problems before customers complain
Most teams track average handle time and resolution rates. That's like checking your pulse while ignoring chest pain. Build monitoring that catches routing decay before it impacts customers.
Early warning metrics:
-
Transfer velocity
Track hourly transfer rates by team. Sudden spikes mean rules are breaking or new issue types emerged. A 25% jump in transfer rate usually precedes customer complaints by 6-8 hours.
-
Queue depth variance
Compare queue depths every 15 minutes. If the technical queue grows while general shrinks, skill routing is too aggressive. If all queues grow equally, you have a capacity problem, not a routing problem.
-
First touch resolution by route
Track whether tickets following each routing path resolve on first response. If Rule A tickets resolve 70% on first touch but Rule B only 30%, Rule B is misidentifying issues.
Weekly routing health checks:
Run these queries every Monday:
-
Which agents received tickets outside their skill tags?
-
What percentage of tickets hit fallback routing?
-
Which rules triggered but led to transfers?
-
How many tickets matched no rules at all?
Plot these on a trend line. Gradual increases indicate rules aging out. Sudden spikes mean something broke.
The 15-minute routing audit:
Pick 10 random tickets from last week. For each one:
-
Check initial routing decision
-
Verify skill match accuracy
-
Count total touches
-
Review transfer reasons
-
Compare resolution time to similar tickets
If more than 3 tickets show routing issues, you need immediate rule adjustments. If more than 5 show problems, freeze all rule changes and audit your entire cascade.
Fixing common misroutes without rebuilding everything
Your routing is broken but you can't shut down support for a full rebuild. Fix issues incrementally while tickets keep flowing.
The surgical rule fix approach:
Identify your worst performing rule — highest transfer rate. Instead of deleting it, add a pre-filter. If the rule sends all "login" tickets to technical support but 60% are actually password resets, add a condition: "login AND NOT password." This preserves the rule's valid matches while cutting out the misroutes.
Apply surgical fixes during low-traffic windows and monitor transfer rates for 48 hours before rolling further changes.
Do this for one rule per day. After a week or two, you've eliminated most systematic misroutes without anyone noticing the changes.
Skill definition rehabilitation:
Skill tags are usually too broad. "Technical support" might cover everything from API help to printer issues. Break each broad skill into 3-4 specific capabilities:
-
Technical → API integration, Database queries, Infrastructure
-
Billing → Subscription changes, Refund processing, Invoice questions
-
Product → Feature requests, Bug reports, Usage guidance
Agents keep their primary skill tag but gain specific secondary tags. Routing becomes more precise without losing fallback options.
The temporary override valve:
When specific issues spike during an outage or product incident, you need escape valves. Create temporary rules that expire automatically:
-
"Route all [specific error] tickets to crisis team for next 48 hours"
-
"Bypass skill matching for [feature] questions this week"
-
"Hold all billing tickets in review queue during migration"
These rules sit above your normal cascade and catch known problems before they contaminate regular routing. When the incident is over, they expire and you're back to normal — no cleanup required.
When hybrid routing makes sense (and when it's overkill)
Not every team needs complex routing. Under 20 agents handling fewer than 200 tickets daily, basic queue management probably works fine. Hybrid routing adds overhead that small teams genuinely can't maintain.
| Signal | Hybrid Routing Needed | Hybrid Routing Is Overkill |
|---|---|---|
| Agent specialization | Agents regularly say "that's not my area" | Every agent can handle 80% of issues |
| Transfer rate | Exceeds 20% | Under 10% |
| Customer satisfaction | Drops for complex issues | Stays consistent across issue types |
| Resolution time | Varies wildly by issue type | Mostly consistent |
| Senior agent usage | Mostly handling escalations, not first contact | Handling a healthy mix of both |
| Team communication | Distributed, async-heavy | Colocated and communicating constantly |
If you're sitting in the middle of that table — some signals pointing each direction — start with Tier 1 deterministic rules only and add skill matching once you can see where tickets are actually breaking down.
Building misroute detection into your operational flow
Manual monitoring catches problems after customers already suffered. Build detection directly into your routing system to catch issues as they happen.
Create circuit breakers for poorly performing rules. If a rule generates transfers more than 30% of the time, automatically demote it to lower priority. The system still uses the rule but checks other conditions first.
Build agent feedback loops. Add a "misrouted" button to your ticket interface. When three agents mark tickets from the same rule as misrouted within an hour, the system alerts managers and surfaces rule modification suggestions.
Track customer signals too. When customers use phrases like "I keep getting transferred" or "nobody seems to know," flag the routing path for review. These tickets often reveal edge cases your rules miss entirely.
Set up automatic rule testing. Every night, run your last 100 resolved tickets through current routing rules. Compare where they'd route today versus where they actually resolved. Significant differences indicate rule drift — your rules are drifting away from reality while the business keeps changing underneath them.
Teams that build this kind of detection in tend to catch somewhere around 75% of routing problems before customers complain. Resolution times stay consistent even as ticket volume and complexity grow.
The real cost of misroutes in your operation
Every misrouted ticket costs more than just time. A typical misroute adds 4-6 hours to resolution. At roughly $30/hour fully-loaded agent cost, that's $120-180 in direct labor waste per ticket. But the real cost comes from cascade effects.
Misrouted tickets create duplicate work. The wrong agent investigates for 15 minutes before transferring. The right agent re-reads everything and investigates again. Sometimes a third agent gets pulled in for escalation. You're paying three people to do one person's job.
Customer impact multiplies costs further. A frustrated customer who gets transferred three times is significantly more likely to churn. If your average customer value is $500/month, one bad routing experience can wipe out real revenue.
Agent morale suffers too. Technical specialists stuck answering password resets burn out faster. Generalists overwhelmed by complex technical issues feel inadequate. Your best people start looking for environments where they can actually use their skills.
Making hybrid routing sustainable with operational software
Manual rule management becomes genuinely unworkable around 50 active routing rules. You need systems that handle rule complexity while keeping visibility and control intact.
Operational platforms powered by AI automation can analyze ticket patterns and surface rule improvement suggestions. Instead of guessing which rules are breaking, the system identifies transfer patterns and misroute trends, then recommends specific adjustments. That's a different kind of value than just routing tickets — it's building institutional memory about what breaks and why.
The key is keeping humans in control while letting automation handle pattern recognition. Your team defines the routing strategy. The system executes rules, monitors performance, and flags anomalies. Managers review suggestions and approve changes instead of manually digging through ticket data every week.
That shift reduces routing maintenance from somewhere between 15-20 hours weekly down to a couple hours of strategic review. Your team focuses on customers instead of managing routing logic.
Operational software doesn't replace your routing strategy — it makes your strategy sustainable as complexity compounds. Rules stay current, skill tags match reality, and misroutes get caught before customers notice.
Moving forward with hybrid routing
Hybrid routing isn't about perfection. It's about building something that degrades gracefully when edge cases appear. Deterministic rules handle the obvious stuff. Skill matching sends specialized issues to the right people. Fallback routing ensures nothing gets stuck.
Teams that make this work share a few traits. They monitor actively instead of reacting to complaints. They fix problems incrementally rather than chasing massive overhauls. They accept that some misroutes will happen but build systems to catch them quickly.
Start with your biggest routing pain point. Maybe it's technical tickets reaching non-technical agents. Maybe it's priority customers stuck in general queues. Pick one problem, implement a focused fix, and measure the impact. Once that's stable, move to the next.
Your routing will never be perfect. But it can be functional enough that customers get help quickly, agents work efficiently, and managers aren't fielding complaints every Monday morning. That's worth more than any perfectly designed system that only works in theory.
Hybrid routing isn't about perfection. It's about building something that degrades gracefully when edge cases appear.
Ready to elevate your customer support?
Join 2,000+ support teams using Helpyly to reduce response times, automate workflows, and deliver outstanding customer experiences.