

Most support teams are stuck in the same frustrating loop. Agents solve the same problems week after week. They file bug reports that go nowhere. Product asks for "more data" while the queue fills with repetitive tickets. Meanwhile, customers hit the same broken workflows for months.
The disconnect comes down to language. Support sees symptoms—angry customers, confusing error messages, broken workflows. Product needs root causes—reproducible steps, affected code paths, user segments. Without something bridging those two realities, tickets pile up while bugs sit untouched.
A subscription box company I worked with had their support team fielding 400+ tickets a week about shipping calculations. Agents documented everything carefully. Product never touched the underlying calculator bug because the tickets read like isolated complaints rather than a systemic failure. Six months in, they were still manually adjusting shipping costs on every third order.
The damage goes beyond wasted hours. When support agents realize their bug reports disappear into silence, they stop bothering to report. When product gets vague "this is broken" messages, they deprioritize. The whole feedback loop collapses. Customers stay stuck with broken experiences, and support teams resign themselves to workarounds that never go away.
Cross-functional contracts: the missing operational infrastructure
A cross-functional contract between support and product isn't a document sitting in a shared drive—it's operational infrastructure that turns every ticket into actionable product intelligence. Think of it as a translation protocol converting support observations into something engineering can actually use.
The contract defines three things most companies never bother to formalize.
Evidence requirements spell out exactly what support must capture to make bugs reproducible. Not "customer couldn't checkout" but browser version, payment method, cart contents, error timestamps, and console logs. Support learns which details matter. Product gets bugs they can actually reproduce.
Response SLAs create accountability on the product side. Within 24 hours, product confirms receipt and assigns priority. Within 72 hours for P1 issues, they provide either a fix timeline or a documented workaround. Support knows their reports get reviewed. Product commits to specific windows.
Success metrics prove the feedback loop is doing anything at all. Not just "bugs fixed" but measurable ticket reduction. If checkout bugs generate 80 tickets weekly, a real fix drops that below 20. Both teams see the operational impact of working together.
Without this contract, even motivated teams fall apart. Support reports bugs inconsistently. Product responds unpredictably. Nobody measures whether fixes actually reduce ticket volume. The contract creates structure where there's usually just chaos.
Mapping ticket fields to reproducible evidence
Standard ticket fields capture customer frustration, not technical reality. "Website broken!!!" tells product nothing useful. "Checkout fails at payment step for Safari users with PayPal selected" gives them somewhere to start.
Never let a customer request slip through the cracks.
Helpyly helps you track, resolve, and optimize every support interaction effortlessly.
- Centralized ticket management
- Automated customer notifications
- Performance analytics dashboard
No credit card required
The challenge isn't convincing agents to write better—it's building ticket workflows that capture diagnostic data automatically. Each ticket type needs specific evidence requirements mapped to custom fields:
| Ticket Type | Required Evidence | Collection Method |
|---|---|---|
| Login Issues | Browser/OS, error message, account status, last successful login | Auto-populated + screenshot |
| Payment Failures | Payment method, amount, error code, transaction ID | API logs + customer input |
| Feature Bugs | Steps to reproduce, expected vs actual behavior, frequency | Guided form + session replay |
| Performance Issues | Page/action affected, load times, network conditions | Performance metrics + user report |
A meal kit delivery service overhauled their bug reporting by adding structured fields. Agents had been writing paragraphs trying to explain issues. After the change, they check boxes and attach screenshots, and product receives tickets with browser console logs, session IDs, and timestamped error messages already included.
The trick is progressive disclosure—agents only see fields relevant to the issue category. Payment problems prompt for transaction IDs. Login failures request browser versions. The system pulls agents toward useful evidence without overwhelming them.
Use progressive disclosure to reduce agent friction while ensuring the right diagnostic data is collected for each ticket type.
Custom fields also surface patterns that free-text descriptions bury. When 47 tickets suddenly share "iOS 17.2" and "biometric login," product spots the correlation immediately. That same pattern is invisible in paragraph-form descriptions.
Product response SLAs that actually work
Most SLA agreements focus on customer response times and say nothing about internal handoffs. Product teams get urgent bug reports and respond... eventually. This unpredictability kills support morale as fast as it damages customer satisfaction.
Functional product response SLAs need three things.
Acknowledgment windows ensure every report gets initial review. Product confirms receipt within 24 hours for standard issues, 4 hours for critical bugs. This isn't resolution—it's just confirmation that someone is looking. Support agents know their reports didn't vanish.
Priority definitions align both teams on urgency. P1 means actively blocking revenue—checkout completely broken, login universally failing. P2 covers degraded experiences affecting 10%+ of users. P3 covers edge cases and minor annoyances. Both teams use identical criteria, which cuts the arguments about severity.
Resolution commitments set realistic fix timelines. P1 issues get same-day patches or documented workarounds. P2 bugs get fixes within a week or approved long-term workarounds. P3 problems enter the regular development cycle with quarterly review. Support can set real customer expectations based on actual engineering capacity.
Without these SLAs, support escalates everything as urgent because they have no visibility into product priorities. Product ignores most reports because they can't tell real crises from minor complaints. Both teams burn out.
A travel booking platform implemented these SLAs after their support team nearly revolted. Agents had reported the same flight search bug 200+ times over three months with zero product response. After establishing 48-hour acknowledgment SLAs and weekly priority reviews, product fixed seven critical bugs within a month. Ticket volume dropped 35% as those fixes eliminated the recurring problems.
Building metrics that prove ticket reduction
The real proof of a closed-loop feedback system isn't bugs fixed—it's tickets prevented. Most companies never connect fix deployment to ticket volume changes. They patch bugs and hope for the best.
Tracking this properly means monitoring tickets at the problem level, not just overall volume.
Start by categorizing tickets by root cause rather than symptom. "Password reset" might come from three different bugs—email delivery failures, reset link expiration, or database sync issues. Track each separately to actually measure fix impact.
Create baseline metrics before fixes go out. If login errors generate 120 tickets weekly, document that. Include distribution patterns—Mondays see 40 tickets, weekends drop to 5. This context prevents false victories from normal variation.
Then track volume for 30 days after the fix. A real fix shows immediate decline—ticket volume drops 70%+ within a week. Partial fixes show gradual reduction. Failed fixes show no change, or a brief improvement before regression.
An online education platform found their fix success rate was only 42% once they started measuring this way. They'd been declaring victory after deploying patches without checking whether tickets actually dropped. Half their "fixed" bugs were still generating significant support load. That visibility changed how engineering handled bug tickets—they don't close them now until support confirms 50%+ volume reduction.
The metrics also reveal fix quality. Complete solutions eliminate 90%+ of related tickets. Band-aids drop volume 30-50% while core issues persist. This helps product teams decide between quick patches and comprehensive rebuilds.
When support feedback actually reaches product
The typical support-to-product feedback flow: agents document issues in their help desk, maybe tag them as bugs, occasionally send summaries. Product reviews these reports when they remember, usually during quarterly planning. By then, context is stale and urgency has faded.
Functional feedback loops need systematic handoffs, not occasional communication. Every week, support and product meet for 30 minutes of bug triage. Support presents top issues by ticket volume. Product assigns priorities and owners on the spot.
During these sessions, support brings the following to the table:
-
Top 5 issues by ticket volume with example tickets
-
New bugs discovered that week with reproduction steps
-
Updates on previous fixes—did they actually work?
-
Emerging patterns that might indicate future problems
Product responds with:
-
Priority assignments for new bugs
-
Fix timelines for acknowledged issues
-
Workaround documentation for unfixable problems
-
Questions about unclear reports
Between meetings, automated systems keep things moving. When tickets tagged as bugs exceed thresholds—say, 20 instances of the same issue—alerts fire to product leads. Escalation paths activate for revenue-impacting bugs. The weekly meeting handles routine issues while automation catches crises before they compound.
Here's a simple workflow visualization for the weekly triage and automated alerts.
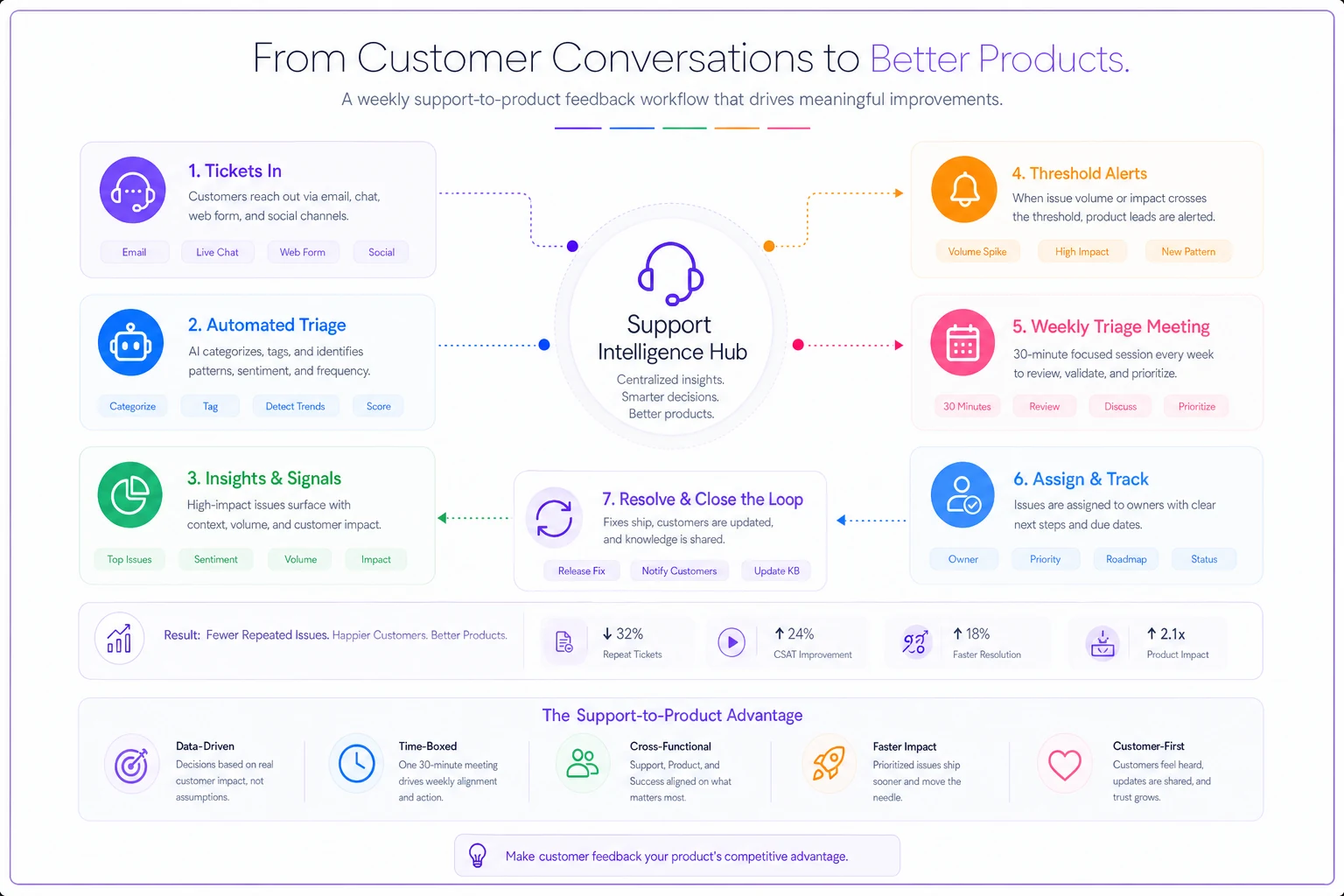
A furniture e-commerce company transformed their feedback loop this way. Previously, support emailed bug reports sporadically. Product reviewed them quarterly at best. After implementing weekly triage sessions and threshold alerts, average bug resolution time dropped from 67 days to 12 days. Support agents also started catching bugs earlier because they knew reports would get reviewed.
The compound effect of fixed bugs on support operations
Every unfixed bug creates operational drag that compounds quietly over time. Agents build workarounds. They write internal documentation. They train new hires on those workarounds. Knowledge bases bloat with band-aid solutions. The whole support operation gradually warps around software defects.
Take password reset bugs. When the automated system fails, agents manually reset passwords—5 minutes instead of 30 seconds for working self-service. They document the manual process. New hires learn it during onboarding. Eventually, 15% of support capacity is going toward a problem customers should be solving themselves.
The real cost isn't just time. It's operational complexity. Every workaround is another process agents have to remember. Training takes longer. Mistakes increase. Quality drops as agents juggle normal procedures alongside bug-specific exceptions.
When bugs finally get fixed, the simplification cascades. Training accelerates because there are fewer exceptions to teach. Agent confidence improves—they solve real problems instead of fighting software. Customer satisfaction goes up because issues resolve properly the first time. Operational costs drop as time per ticket falls and escalations thin out.
A subscription software company tracked this after fixing their billing calculation bug. The bug had generated 300+ monthly tickets for eight months. Average handle time was 12 minutes, including explanation and manual adjustments.
After the fix, billing tickets dropped to under 40 monthly. Average handle time fell to 4 minutes. Agent turnover dropped 20% over the following quarter. Training time for billing issues went from 3 hours to 45 minutes.
The operational improvement was bigger than the direct time savings. Agents stopped dreading billing tickets. Customers stopped threatening cancellations over calculation errors. The whole atmosphere in support shifted.
Creating accountability without finger-pointing
Cross-functional contracts fall apart when they become blame documents. "Product missed their SLA" or "Support didn't provide reproduction steps" turns collaboration into conflict fast. The contract should create transparency, not ammunition.
Structure accountability around shared outcomes rather than individual failures. Instead of tracking SLA violations, measure bugs resolved within SLA. Instead of counting incomplete support reports, track reports with successful reproduction. Focus on what went right.
When SLAs slip, investigate the system rather than the person. Product missing response deadlines usually signals capacity problems or unclear priority criteria—not lazy engineers. Support providing vague reports usually means inadequate tools or training—not incompetent agents.
Weekly reviews should follow a no-blame format:
-
Celebrate wins—bugs fixed, tickets reduced
-
Review misses as process failures—what got in the way?
-
Identify system improvements—tools, workflows, training
-
Commit to specific changes—who does what by when
A logistics software company learned this the hard way. Their initial contract included penalty clauses—teams losing budget for SLA violations. Within two months, both teams were gaming metrics instead of fixing problems. Product marked bugs "not reproducible" to avoid SLAs. Support stopped reporting complex issues to protect their scores.
They restructured around shared goals: 25% reduction in repetitive tickets, 48-hour average bug acknowledgment, 80% reproduction success rate. Both teams owned all metrics jointly. Within six months, they exceeded every target.
Technology and tools: from spreadsheets to automated workflows
Most companies try managing this process through spreadsheets and weekly emails. Support keeps bug logs. Product maintains priority lists. Someone manually cross-references ticket volumes with fix deployments. It works for about three weeks before everyone abandons it.
The contract needs operational infrastructure that automates evidence collection, SLA tracking, and impact measurement. Modern support platforms can handle most of this through configuration.
Ticket field automation pulls diagnostic data without agent input. Browser details, account status, and session information populate automatically. Agents focus on capturing customer-specific context rather than technical specs.
Bug aggregation workflows group similar issues automatically. When five tickets mention "checkout error 4001," they link to a single bug report. Product sees frequency immediately. Support agents know which issues are already in the system.
SLA monitoring tracks product response time without anyone doing math. When bug reports age past acknowledgment windows, alerts fire. Dashboards show SLA trends. Neither team manually calculates compliance.
Impact measurement connects fix deployments to ticket volumes. When product marks a bug resolved, the system watches related ticket frequency for 30 days. Success metrics calculate on their own.
Mid-sized companies can implement this with existing tools. An online marketplace built their entire system using their help desk's native workflow automation and reporting. Two weeks of setup, no custom development. Start simple—basic field mapping and manual SLA tracking first. Add automation as patterns emerge. Don't try to build the perfect system on day one.
Beyond bugs: using the contract for feature requests and improvements
The same structure that handles bugs can work for feature requests and process improvements. Support sees customer friction that doesn't qualify as bugs—confusing interfaces, missing features, workflow gaps. This intelligence is often more useful than formal user research.
Feature feedback needs different evidence standards than bug reports. Instead of reproduction steps, capture use case frequency. Instead of error messages, document what customers are actually trying to accomplish. Instead of technical diagnostics, provide business impact.
A B2B software company expanded their contract to cover feature intelligence. Support tracked every request with customer segment (enterprise, mid-market, SMB), frequency (daily, weekly, one-time need), workaround difficulty (impossible, complex, simple), and revenue impact (blocker, friction, nice-to-have). Product committed to monthly feature feedback reviews. They acknowledged all requests within a week, gave development decisions within a month, and shared roadmap updates quarterly. Support could actually tell customers whether requests were planned, rejected, or under consideration.
The systematic tracking revealed things nobody expected. Features that sounded critical in sales calls barely showed up in support tickets. Meanwhile, "minor" workflow gaps dominated daily friction. Product shifted priorities based on actual usage patterns rather than theoretical user stories.
Measuring success: from ticket deflection to operational excellence
Success metrics for closed-loop product feedback go deeper than simple ticket reduction. Volume matters, but the operational transformation is broader.
Ticket deflection rate improves as bugs disappear and self-service actually works. Track what percentage of issues customers resolve without an agent. When password reset bugs get fixed, self-service success should jump from 60% to 90%+.
First contact resolution increases when agents stop fighting software bugs. Instead of "we're looking into it," agents give real answers. FCR should climb 15-20% as common bugs disappear.
Agent satisfaction rises when their feedback creates visible change. Survey agents quarterly on whether their bug reports actually matter. Scores below 40% indicate a broken feedback loop. Successful contracts push satisfaction above 70%.
Time to resolution for bugs drops from months to weeks. Track median time from first report to deployed fix. Healthy operations resolve P1 issues within days, P2 within weeks. Anything longer suggests a process problem somewhere.
Support operational cost per ticket decreases as complexity drops. When agents stop maintaining workarounds and managing bug-related escalations, cost per ticket can drop 20-30%. This shows up in reduced training time, faster resolutions, and fewer incident-driven surges.
An enterprise software company tracked these metrics for two years after implementing their contract. Year one focused on basic bug reduction—ticket volume dropped 34%. Year two revealed the compounding: FCR increased 22%, agent satisfaction hit 78%, and cost per ticket dropped $4.30. The downstream improvements dwarfed the direct ticket reduction.
Companies with functioning support-to-product feedback loops operate differently. They fix problems before customers complain en masse. They prioritize improvements based on actual usage. They prevent support costs from compounding as they scale.
The contract isn't really about SLAs and dashboards—it's about building infrastructure for continuous improvement. Support becomes a sensor network catching product issues early. Product gets direct signal about where customers are actually struggling. Both teams move in the same direction instead of around each other.
Most companies never build this because it requires cross-functional cooperation that feels harder than it is. Support and product report to different leaders with different incentives. The contract makes collaboration systematic rather than dependent on whoever happens to get along that quarter.
Starting small beats waiting for a perfect plan. Pick five high-volume bug categories. Define evidence requirements for just those. Set SLAs for P1 issues only. Measure ticket reduction for fixed bugs before expanding to features. Build momentum through visible wins.
The companies that get this right spend less on support while delivering better customer experiences. They fix the right problems based on real data. They catch friction early instead of reacting to churn. In markets where customer experience separates winners from everyone else, a functioning feedback loop between support and product isn't a nice operational improvement—it's a genuine competitive advantage. The contract just makes it repeatable.
Ready to elevate your customer support?
Join 2,000+ support teams using Helpyly to reduce response times, automate workflows, and deliver outstanding customer experiences.

