

Most support to engineering handoffs fail before engineering even opens the ticket. Not because engineers don't care—but because the ticket lands in their queue missing the exact details they need to reproduce the issue.
Why most bug escalations die before engineering ever opens them
A support agent writes "customer can't export reports" and marks it high priority. Engineering tries to reproduce it, can't, asks for more details, waits three days for a response, gets partial information, tries again, still can't reproduce it, and eventually closes the ticket as "unable to reproduce." Meanwhile, seventeen more customers hit the same bug.
The problem isn't communication or willingness. It's that most organizations never define what "reproducible evidence" actually means. Support doesn't know what engineering needs. Engineering doesn't know what support can realistically capture. And customers keep hitting the same unresolved issues week after week.
We've seen support teams sending 40+ tickets per week to engineering with less than 15% getting fixed. Not because the bugs weren't real—follow-up analysis showed most were legitimate issues affecting dozens of customers. They just weren't documented in a way that made them actionable.
Why handoffs break down at the evidence stage
Support agents operate in reactive mode. A customer messages about a broken feature, the agent tries to help, maybe finds a workaround, logs a ticket if it seems serious, then moves on to the next customer. By the time they actually create the engineering ticket—often hours or days later—critical context is already gone.
Never let a customer request slip through the cracks.
Helpyly helps you track, resolve, and optimize every support interaction effortlessly.
- Centralized ticket management
- Automated customer notifications
- Performance analytics dashboard
No credit card required
Engineering needs specifics that support rarely captures naturally. What exact sequence of actions triggered the bug? What was the state of the account when it happened? Were there any console errors? What browser and version? Support agents aren't trained to think like QA engineers, so they capture what seems important to them—usually the customer's frustration level—rather than the technical breadcrumbs engineering actually needs.
The worst part is what this pattern does over time. Support assumes engineering won't fix most bugs they report. Engineering assumes support tickets won't have enough information. So support stops reporting edge cases, engineering stops digging into vague tickets, and bugs accumulate until they cause a major incident.
The minimal evidence template that changes everything
After looking at thousands of support to engineering handoffs across different companies, the same pattern shows up: tickets with these five specific elements get fixed roughly 4x more often than tickets without them.
Required Evidence Fields:
-
Exact reproduction steps (numbered, starting from login)
-
Expected vs actual behavior (one sentence each)
-
Affected customer details (account ID, subscription type, any custom settings)
-
Environmental data (browser, OS, timestamp of occurrence)
-
Supporting evidence (screenshot, video, or error message)
That's it. Not twenty fields. Not a novel-length description. Just these five elements captured consistently.
Here's what an actual ticket looks like with this template:
Ticket #4521: Export function returns blank file for filtered date ranges
Reproduction steps:
-
Log into account (any user role)
-
Navigate to Reports > Sales Summary
-
Set date filter to "Last 30 days"
-
Add product filter for "Category
Electronics"
-
Click "Export as CSV"
-
Open downloaded file
Expected behavior: CSV contains filtered sales data for electronics in last 30 days
Actual behavior: CSV downloads but contains only headers, no data rows
Affected customers:
-
Account ID
18234 (Premium tier)
-
Account ID
18457 (Premium tier)
-
Account ID
17890 (Standard tier)
-
Reported 8 times in last 72 hours
Environment:
-
Chrome 119.0.6045.105
-
Windows 11
-
First reported
2024-01-15 14:32 UTC
-
Still occurring as of
2024-01-18 09:15 UTC
Evidence: [Screenshot showing empty CSV file attached]
Compare that to the typical ticket: "Multiple customers reporting export issues. High priority!!!"
The structured version takes maybe three extra minutes to write but saves hours of back-and-forth between teams.
Priority heuristics that prevent everything becoming "urgent"
Support agents mark the majority of bugs as high priority. Everything feels urgent when a frustrated customer is in front of you. But when everything is urgent, nothing gets proper attention.
| Priority | Fix Target | Criteria |
|---|---|---|
| P1 | Within 4 hours | Blocks core function for 10+ customers, prevents revenue collection, data loss, security exposure, or complete outage |
| P2 | Within 24 hours | Degraded experience for 10+ customers, workaround requires support intervention, affects high-value segment |
| P3 | Within 72 hours | Cosmetic issues, affects fewer than 10 customers, simple workaround available, edge case scenarios |
| P4 | Next sprint | Feature improvements, performance optimizations, documentation issues, nice-to-have fixes |
The key is making priority about customer count and revenue impact, not individual customer frustration. A furious enterprise customer experiencing a cosmetic bug might feel like Priority 1 to support, but if it doesn't block business operations, it's Priority 3.
Some teams resist this framing because it feels cold. It isn't. Clear priorities mean real problems get fixed faster. That enterprise customer's cosmetic issue gets fixed in three days instead of sitting in an "urgent" queue for three weeks behind fifty other "urgent" tickets.
Building the evidence-gathering workflow
The template means nothing if agents can't reliably collect the information. Most support tools aren't built for systematic evidence collection—they're built for conversation management.
Start by creating a simple evidence checklist that agents can follow while on chat or calls. Not after. During. The information degrades quickly once the customer is gone.
Live Evidence Collection Process:
-
Ask them to reproduce the issue while you watch
-
Request a screen share if possible
-
Have them narrate each step as they go
-
Screenshot or record the key moments
-
Note the exact timestamp when the error occurs
-
Copy any error messages verbatim
-
Grab their account ID and browser info before they disconnect
The recording doesn't need to be perfect. A shaky phone video of their monitor works better than no evidence at all.
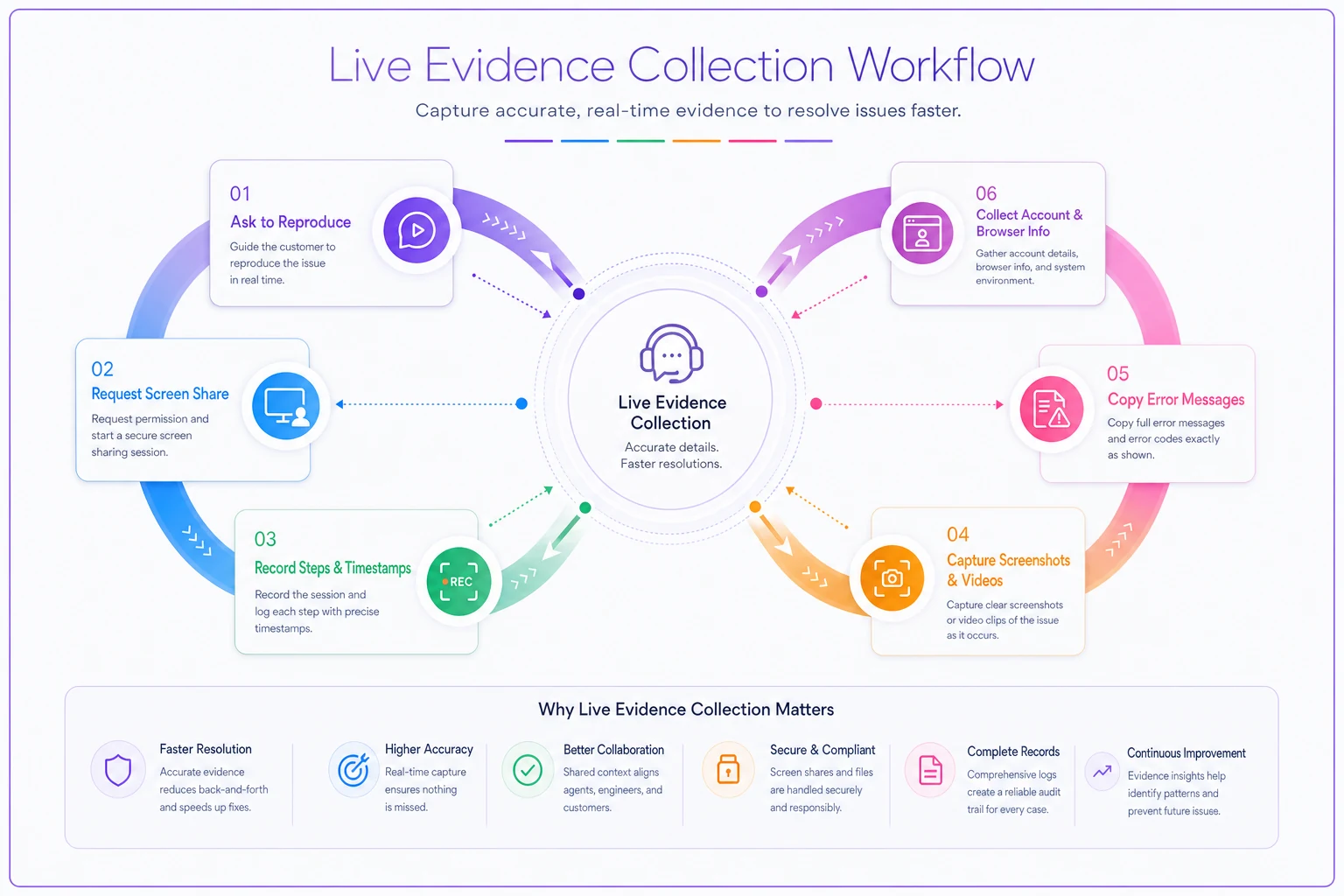
This diagram shows the workflow agents should follow during a live session.
For async tickets where live collection isn't possible, a simple follow-up template works well:
"Hi [Name], I want to make sure our engineering team can fix this quickly for you. Could you help me with a few specific details: Can you list the exact steps you took before seeing this error? What were you expecting to happen? Could you take a screenshot of what you're seeing? What browser are you using? This helps us reproduce and fix the issue faster."
Around 70% of customers will provide this when asked directly. The other 30% won't—but that's still better than 0%.
The verification step everyone skips
Here's what typically happens: engineering fixes a bug, marks the ticket resolved, deploys the fix. Two weeks later, support gets the same complaint.
Post-fix verification isn't just checking that code deployed successfully. It's confirming the original customer problem actually got solved.
Three-Layer Verification Process:
Layer 1: Engineering verification
-
Developer reproduces original bug using ticket steps
-
Confirms bug no longer occurs after fix
-
Tests related scenarios for regression
-
Documents what was actually fixed
Layer 2: Support verification
-
Support agent tests using original reproduction steps
-
Tests with different account types and permission levels
-
Confirms fix works in production environment
-
Creates internal note about what to tell customers
Layer 3: Customer verification
-
Contact originally affected customers
-
Ask them to verify the issue is resolved
-
Document any remaining edge cases
-
Update knowledge base with resolution
Most teams stop at Layer 1. Engineering confirms their code works and moves on. But the customer who originally reported the issue might be using the feature in a way engineering never tested.
One ecommerce platform fixed a checkout bug that prevented purchases over $500. Engineering verified it worked. Support verified it worked. Customers still complained. The fix only applied to USD transactions—international customers using other currencies still hit the bug. Nobody caught it because nobody verified with actual affected customers.
Common handoff failures and their fixes
The "Intermittent Bug" Trap
Support writes: "Customer says search sometimes doesn't work."
Engineering can't reproduce intermittent issues without pattern data. Fix: require agents to document frequency. "Occurs 3 out of 10 attempts" or "Only happens Monday mornings" or "Affects searches for products with special characters."
The "Multiple Issues" Ticket
Support writes: "Customer having various problems with reporting module."
Engineering doesn't know where to start. Fix: one ticket per bug, even if the same customer reported multiple issues. Link related tickets but keep them separate.
The "Works For Me" Response
Engineering tests with their admin account and can't reproduce an issue that only affects limited-permission users. Fix: always include account type, permission level, and any custom settings in the ticket. Test with an account that matches the affected customer's actual setup.
The "Silent Fix" Problem
Engineering fixes the bug but doesn't tell support. Support keeps offering workarounds for an already-fixed issue. Fix: require engineering to comment on the original ticket when deployed, not just mark it closed. Include what was fixed and any limitations.
SLA expectations that both teams can actually meet
SLAs become meaningless when they're not achievable. Setting a 2-hour response time for all engineering tickets just trains everyone to ignore them.
| Priority | Initial Acknowledgment | Resolution Target |
|---|---|---|
| P1 | Within 30 minutes | 4 hours (or documented workaround) |
| P2 | Within 2 hours | 24 hours |
| P3 | Within 8 hours | 72 hours |
| P4 | Within 24 hours | Next sprint |
The acknowledgment SLA matters as much as resolution. Support needs to know engineering received and understood the ticket. A simple "Reproduced, investigating" comment prevents escalation spirals that waste everyone's time.
For bugs that can't be fixed within SLA, require a workaround to be documented. Maybe the full fix takes two weeks, but if support knows to tell customers to use Firefox instead of Safari in the meantime, that's manageable.
Making the handoff checklist stick
Creating a support to engineering handoff checklist is easy. Getting teams to use it consistently is where things fall apart.
The template becomes optional the moment an agent successfully escalates a vague ticket. If "customers can't login!!!!" gets engineering attention, why spend time writing detailed reproduction steps?
Enforcement Mechanisms:
Technical enforcement: Configure your ticketing system to require the five evidence fields before a ticket can be assigned to engineering. No fields, no escalation.
Quality scoring: Review a sample of handoff tickets weekly. Score them on evidence completeness. Share scores with the team—not to shame anyone, but to track progress over time.
Engineering pushback: Give engineering permission to reject tickets missing critical information. Not rudely, but firmly: "Need reproduction steps to investigate. Please update ticket with steps from template."
Success metrics: Track fix rate, not ticket volume. "We escalated 50 tickets" means nothing. "We got 15 customer-reported bugs fixed" means something.
When a major customer issue comes in, the process often breaks down. Teams bypass the checklist because "this is urgent." That's exactly when you need it most. During incidents, clear reproduction steps help engineering fix issues faster when every minute counts. We covered incident-specific handoff protocols in our ticket surge response playbook, but the core evidence requirements remain the same.
Real implementation at a 50-agent support team
A software company with around 50 support agents was escalating 30-40 bugs weekly to engineering. Maybe 3-4 got fixed each week. The rest sat in backlog or got closed as "cannot reproduce."
They implemented this checklist and verification process. The first week was rough—agents complained about the extra work, engineering complained that tickets still lacked detail. By week three, something shifted.
Tickets took agents an extra 2-3 minutes to write but included everything engineering needed. Engineering stopped asking follow-up questions. Fix rate jumped from under 10% to around 35% within a month.
More importantly, duplicate reports dropped. When bugs actually get fixed, support stops seeing the same issues repeatedly. The team went from 30-40 escalations weekly to 15-20, but with a much higher fix rate.
The verification step caught real issues too. About 20% of "fixed" bugs weren't fully resolved—they worked in engineering's test scenario but failed in specific customer contexts. Catching these before closing tickets prevented the frustration of customers reporting the same supposedly fixed bug a week later.
Six months in, they were holding a 40-45% fix rate on escalated bugs. Not perfect, but a genuine improvement from where they started. Customer satisfaction scores specifically related to technical issues improved by 12 percentage points.
When automation helps (and when it doesn't)
The temptation to fully automate the support to engineering handoff is understandable. AI can categorize issues, suggest priorities, even draft reproduction steps from chat transcripts. Full automation usually makes the problem worse, though.
AI-generated reproduction steps miss critical nuance. The customer said "I clicked export" but didn't mention they'd filtered the data first. Automated tools capture the obvious and miss the subtle detail that actually matters.
Where automation genuinely helps:
-
Auto-population of known fields Pull account ID, browser info, and subscription tier automatically from your support tool. Agents shouldn't manually enter data that systems already have.
-
Screenshot and video capture tools Built-in screen recording that automatically attaches to tickets saves a lot of time. Agents click one button during the call and everything gets captured.
-
Duplicate detection Before creating a new engineering ticket, surface similar issues already in the system. Show agents: "3 similar bugs reported this week—link to existing ticket?"
-
Priority suggestions Based on customer count and account types affected, suggest a priority level. Agents can override, but starting from a data-driven recommendation helps.
-
Verification reminders Automatically remind engineering to verify fixes, remind support to test resolved tickets, and prompt both teams to close the loop with affected customers.
The goal is automating the mechanical parts while keeping human judgment for the complex ones. Agents still need to understand the customer's actual problem. Engineering still needs to determine root cause. Neither team should waste time on repetitive data entry or manual follow-ups.
One platform used AI to pre-fill the handoff template based on chat transcripts, with agents reviewing and correcting before escalating. This cut ticket creation time by roughly 40% while maintaining quality. The AI handled the format, humans handled the substance.
The difference this makes long-term
Six months after implementing a proper handoff checklist, the dynamic between teams changes noticeably.
Support stops feeling like they're shouting into a void. When bugs they report actually get fixed, agents become more diligent about capturing good evidence. They start recognizing patterns, catching issues earlier, providing better context.
Engineering stops dreading the support ticket queue. Instead of vague complaints they can't action, they get clear, reproducible issues they can actually fix. Less time asking questions, more time shipping solutions.
Customers notice too. Bugs that used to persist for months get resolved in days. Issues that would have affected hundreds get caught when they're still affecting tens.
The compound effect is real. Fewer bugs means fewer support tickets. Fewer tickets means agents have more time to properly document the bugs they do find. Better documentation means higher fix rates. Higher fix rates mean fewer future tickets. The cycle runs in the right direction instead of the wrong one.
Support teams that commit to this approach often cut engineering escalations by around 50% over a year—not by ignoring bugs, but by actually fixing them. The relationship between support and engineering stops being adversarial and starts being something closer to functional.
Moving forward with your checklist
Start small. Don't try to overhaul your entire handoff process overnight.
Pick your five most critical evidence fields. Train a few agents on the template. Have engineering commit to prioritizing tickets that follow the format. Run it for two weeks and measure how many tickets get fixed versus before. Then adjust the template based on what engineering actually needs—not what you assume they need. Some teams need error codes, others need user permissions, others need data samples.
The perfect handoff checklist for your team won't match this template exactly. But it will share the same core elements: reproducible steps, clear evidence, realistic priorities, and a verification process that closes the loop.
Once the basic checklist is working, layer in automation. Add the verification steps. Refine the priority matrix. But get the fundamental handoff right first.
Even moving from a 10% fix rate to 25% transforms the customer experience. Support agents who see their escalations creating real fixes become better at their jobs. Engineers who receive actionable tickets become more responsive to customer issues. The support to engineering handoff checklist seems like a small operational detail, but in practice it's the difference between bugs accumulating until they cause major incidents and bugs getting fixed before most customers notice them—and the difference between support and engineering blaming each other and both teams actually improving the product together.
Ready to elevate your customer support?
Join 2,000+ support teams using Helpyly to reduce response times, automate workflows, and deliver outstanding customer experiences.

